“未曾试图摘星捧月,但期望月亮奔我而来。”
Python 爬虫:爬取 Bilibili 壁纸喵的相册图片
前言
5121428 默哀,RIP🕯️
之前我们在Python 爬虫入门:爬取自己的博客文本中爬取了文本,现在来爬一爬图片。
目标是Bilibili 官号壁纸喵的空间相册中的图片:壁纸喵的相册空间
爬取文字和图片的区别
图片的读写和文本不同,在 Python 中进行图片读写的时候,需要规定'b'来表示二进制模式。
其实网络传输和存储的时候用的都是二进制啦,比如我们用一些软件(比如Notepad++)打开图片或 txt 文件都可以看到其十六进制的内容(因为二进制太长了所以会转成十六进制,本身内容是一样的)
得益于不同的文字有着各种各样的编码解码(比如 ASCII 码,BIG5 码,Unicode 码等),我们可以轻松地将二进制内容变为我们所熟悉的字符,因此我们可以直接在控制台输出爬取到的字符,而非二进制内容。这是因为系统在中间悄悄地帮我们进行了编码解码,然后在控制台进行输出。
自然,我们是不能在命令台输出图片的。图片文件(jpg、png、webp)有着自己的格式,有着其所规定的文件头或文件尾啥的,因此需要通过特定的软件来打开文件。这些软件会根据规定的格式来获取图片大小、颜色等信息,并将其构建出我们眼前的图片(这些信息都在图片的二进制内容中)。
这也是为什么记事本或控制台看不了图片——他们不会从中获取这些信息,也不存在什么编码能将图片输出,因此我们在控制台输出的只能是其二进制本体。
说了这么多有的没的,其实就一句话,我们下载图片的时候要用二进制模式,并且过程中我们是看不到图片的样子的嘞。
知识点补充
其实只要会了上一篇内容里涉及的知识其实就差不多了,不过在爬取的过程中,发现其图片的url并没有直接放在页面上,而是通过额外发送请求来获取的。返回的结果是一个JSON 对象,因此我们需要用 Python 的json 库对其进行处理,而不需要对页面节点进行操作。所以BeautifulSoup暂时失去了用武之地,Python 内置的json 库趁机上位。
此外,我们在读写文件的时候,需要用二进制模式(b)而不是默认的文本模式(t),毕竟是图片嘛。
剩下的难点集中在寻找 url和分析返回体结构上,我们在下面边做边看。
Python 创建目录
很多小伙伴不想把我们爬取到的文章或图片全部一股脑地堆在根目录,劳资就是想要分类。但是 Python 的open()方法接受文件的时候如果前缀的文件夹不存在是会直接报错的,不会主动给咱创建文件夹,这时候就要用其他方法帮助我们创建文件夹了
主要用到os 包的这三个方法:
os.path.exists(path):判断 path 目录(文件夹)是否存在,存在则返回Trueos.mkdir(path):创建指定目录os.makedirs(path):创建指定多层目录(文件夹和子文件夹)
因为如果目录已存在,我们再创建也是会报错的(FileExistsError),所以通常习惯在创建之前用exists()判断一下
如果我想在根目录创建一个image的文件夹:
dir_path = 'image/'
if not os.path.exists(dir_path):
os.mkdir(dir_path)
又因为如果上级目录不存在,比如我想在image文件夹里创建一个background文件夹,即image/background,但是image目录不存在,那么也是会报错的(FileNotFoundError),这时候就要用到makdirs()了
当然也可以用两个mkdir()先创建image再创建background,但那也太不智能了,不够优雅;>
dir_path = 'image/background/'
if not os.path.exists(dir_path):
os.makedirs(dir_path)
最后提一嘴,mkdir()和makrdirs()都有一个默认的参数mode,用于配制我们创建的目录的权限,默认mode=0o777,表示 777 权限,即可读可写可执行。权限及其数值表示具体可见Linux 权限及 chmod 命令
Python 操作 JSON 对象:json 库
对于 JSON 对象的操作,Python 自带了一个内置库json,其实主要的就两个方法,简单好用。
(其实在后面的例子中用不到,因为request的json()方法直接帮我们转了……但还是可以了解一下的)
json.dump()用于将一个对象转换成JSON 对象(字符串),它的参数太多了,加上默认值写出来得占两三行所以就不一一介绍了,反正也不一定都能用得到。
其中有个参数indent用到的比较多,表示在输出的时候会进行缩进从而美化输出。默认值为None,表示紧凑输出(就是不换行);如果是非负整数或者字符串(如\t)则会按照所给值对每一层进行缩进
import json
data = {
'name': 'blackdn',
'age': 18,
'hobbies': {
'sports': 'running',
'food': 'hamburger'
},
}
json_data = json.dumps(data)
print(json_data)
# {"name": "blackdn", "age": 18, "hobbies": {"sports": "running", "food": "hamburger"}}
json_data_with_indent = json.dumps(data, indent=4)
print(json_data_with_indent)
# 输出:
{
"name": "blackdn",
"age": 18,
"hobbies": {
"sports": "running",
"food": "hamburger"
}
}
json.loads()则是反过来,如果我们收到一个 JSON 对象,可以将其转为一个Python 对象(键值对)。JSON 的key就是对象的属性,value就是对象的值
object_data = json.loads(json_data)
print(object_data)
# {'name': 'blackdn', 'age': 18, 'hobbies': {'sports': 'running', 'food': 'hamburger'}}
print(object_data['name'])
# blackdn
小试身手
寻觅 URL
先别急着写代码,我们都知道爬虫第一步是通过requests获取数据,那么我们得知道我们要从哪里获取想要的东西——至少得先看看图片的 url 在哪,长啥样
在空间的相册页面,我们可以看到一个图片投稿包含两个链接,分别表示详情页的链接和缩略图的链接:
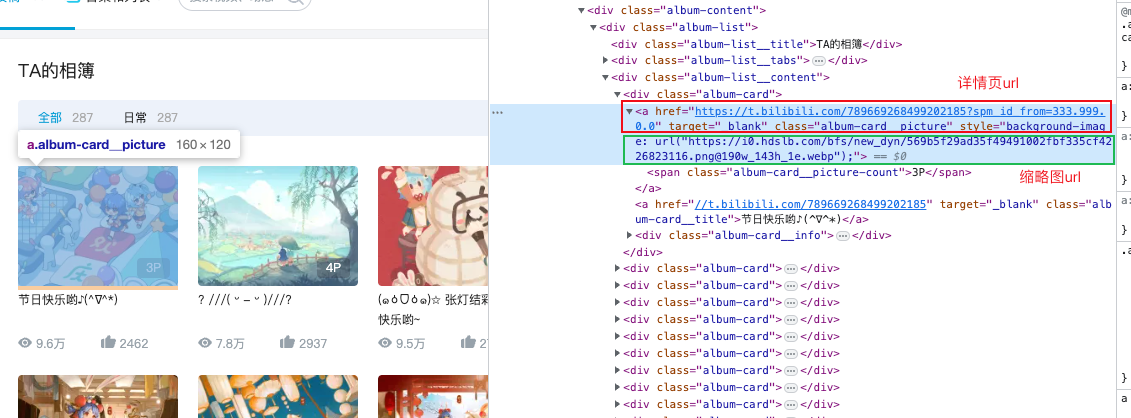
显然,这两个都不能拿来直接用。详情页需要再点进去找图片的 url,而缩略图的分辨率很低,无法拿来当壁纸欣赏。
于是我们退一步,想想这些图片是哪来的——什么时候会加载这些图片呢?自然是翻页的时候,那么就来看看翻页的时候进行了什么请求:
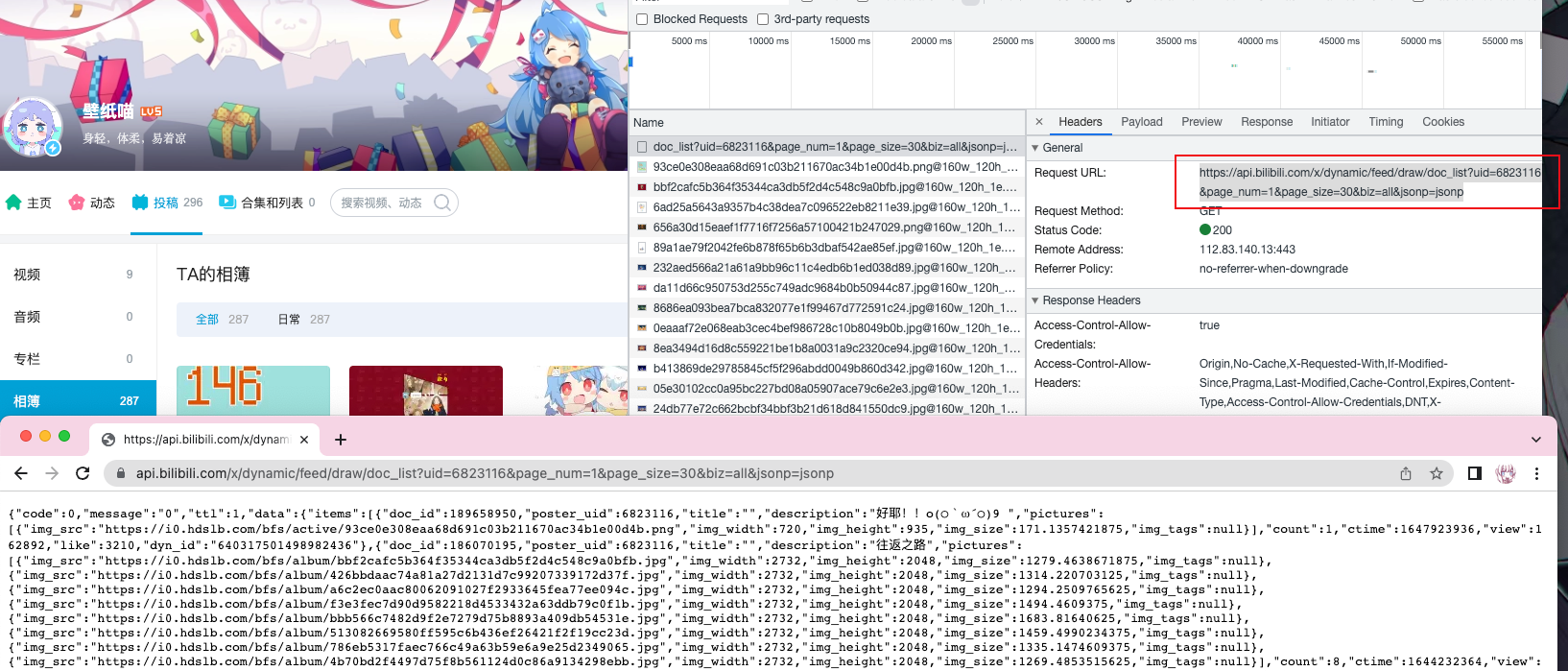
我们发现,当点击翻页的时候,会发送一个 GET 请求:
url_to_get_page = f'https://api.bilibili.com/x/dynamic/feed/draw/doc_list?uid=6823116&page_num={page_number}&page_size=30&biz=all&jsonp=jsonp'
这个请求会将当前页的所有图片信息都返回。而且仔细观察这个请求,当我们点击不同按钮的时候,唯一变化的参数只有page_num,也就是说,我们只要控制这个参数,就可以直接构建 url,不需要在页面上寻找,也不需要一个一个详情页点进去了。
要注意的是,翻页的page_num参数是从0开始的,即第一页page_num = 0,第十页page_num = 9
分析结构
我们先看看请求返回的是啥东西:
{
"code": 0,
"message": "0",
"ttl": 1,
"data": {
"items": [...]
}
}
显然其中只有data是我们需要的,data中只有一个名为items的列表,而这个列表就对应着空间相册当前页的所有图片信息
我们取其中一个对象看看:
[
{
"doc_id": 239076960,
"poster_uid": 6823116,
"title": "",
"description": "节日快乐哟♪(^∇^*)",
"pictures": [
{
"img_src": "https://i0.hdslb.com/bfs/new_dyn/569b5f29ad35f49491002fbf335cf4226823116.png",
"img_width": 1280,
"img_height": 2560,
"img_size": 2102.0810546875,
"img_tags": null
},
{
"img_src": "https://i0.hdslb.com/bfs/new_dyn/39b6f79b2e9e5cf9aa2664b62427167b6823116.png",
"img_width": 1600,
"img_height": 2560,
"img_size": 2309.630859375,
"img_tags": null
},
{
"img_src": "https://i0.hdslb.com/bfs/new_dyn/245f633c93de035942c388958db68bcc6823116.png",
"img_width": 2732,
"img_height": 2048,
"img_size": 3912.3623046875,
"img_tags": null
}
],
"count": 3,
"ctime": 1682697606,
"view": 96298,
"like": 2463,
"dyn_id": "789669268499202185"
},
{...},
{...},
...
]
每个item都对应着一个投稿,其包含了稿件id(doc_id),用户id(poster_uid),投稿标题和文字内容(title / description),图片数量(count),点击量(view),点赞量(like),时间戳等。
当然还包括我们所需的每张图片信息(pictures),其包含了图片url,图片的长宽(img_width / img_height)和大小(img_size,亲测单位是KB)等信息。
开始写码
因为是壁纸喵,所以先给个文件夹(./miao)存一下我们的图:
if __name__ == '__main__':
dir_path = 'miao/'
if not os.path.exists(dir_path):
os.mkdir(dir_path)
然后,我们已经知道了获取我们图片 json 对象的请求 url,而我们需要做的仅仅是修改 url 中的page_num参数——而从页面得知,这个参数的取值是 0 ~ 10,所以:
page_number = 0
last_page_number = 10
for current_page in range(page_number, last_page_number):
url_to_get_page = f'https://api.bilibili.com/x/dynamic/feed/draw/doc_list?uid=6823116&page_num={current_page}&page_size=30&biz=all&jsonp=jsonp'
print(f'We are in page {current_page}')
我们通过格式化字符串f-string将变量嵌入请求的 url 中,然后每次请求完让其+1——这使得我们可以通过构建的方式来获得后续 url,而不用在 html 页面上查找,这让我们的访问方便了许多。
然后的事情我们就比较熟悉了,先通过requests获取数据,然后在返回体 -> data -> items中获取我们想要的图片 url,再用requests访问图片 url,写入本地。
因为我们知道请求返回的是 JSON 格式的数据,所以我们通过requests 中 Response 对象的json()方法直接将结果转为JSON 对象,从而直接获取其内容:
# only crawl 3 pages
for current_page in range(3):
url_to_get_page = f'https://api.bilibili.com/x/dynamic/feed/draw/doc_list?uid=6823116&page_num={current_page}&page_size=30&biz=all&jsonp=jsonp'
print(f'We are in page {current_page}')
response_page = requests.get(url_to_get_page)
response_page_json = response_page.json()
img_list = response_page_json['data']['items']
# only crawl 5 images in each page
for img_index in range(5):
for index, pics in enumerate(img_list[img_index]['pictures']):
img_name = f'page{current_page}-img{img_index}-{index}.jpg'
img_url = pics['img_src']
img_response = requests.get(img_url)
with open(f'{dir_path}{img_name}', 'wb') as f:
f.write(img_response.content)
print(f'download {img_name} successfully')
为了省点流量方便快捷,上面只爬取了前三页的内容,每页只爬取前五个投稿的图片(喵的 8MB 的图片我都得下 20 秒)
如果想要爬取全部页面(10 页),改成原来的就行:for current_page in range(page_number, last_page_number):
如果想要爬取一页的全部投稿图片,可以直接遍历img_list,不用像上面示例中一样只获取前五个投稿(for img_index in range(5) )
这个爬虫嵌套了三层循环,分别对应遍历全部页面、遍历当前页面的全部投稿、遍历当前投稿的全部图片。是的,每个投稿里可能还包含多个图片。
由于我们需要将图片下载到本地,所以要确保每个图片的命名都是独一无二的,这里采用页码-投稿的当前页下标-图片在投稿的下标的形式,所以用到了内置函数enumerate()来同时遍历下标和本体(for的第一个参数为下标,第二个参数为本体)
筛选图片
我们发现,每个投稿中都有包含着许多图片,有的是有不同的长宽尺寸,来作为手机或电脑壁纸;还有分为有文字和没有文字的版本等。
比如我现在只想要电脑壁纸,要怎么处理呢?我们发现在data -> items -> pictures中,每个item都包含了宽高的值,因此我们可以进行判断,只下载宽度大于高度的图片:
for index, pics in enumerate(img_list[img_index]['pictures']):
img_name = f'page{page_number}-img{img_index}-{index}.jpg'
# skip if width < height
if pics['img_width'] < pics['img_height']:
print(f'skip {img_name}')
break
img_url = pics['img_src']
img_response = requests.get(img_url)
with open(f'{dir_path}{img_name}', 'wb') as f:
f.write(img_response.content)
print(f'download {img_name} successfully')
当然,条件反一下你就可以只得到手机壁纸啦
后话
老样子,代码上传到 Github 了:PythonCrawlerForStudy,改进了一点代码(本来也不多),加了些注释和参数啥的,不过大致思路都一样。说实话代码量比想象中的要少很多。
其实能像这样比较简单地爬到这些图片属实运气比较好,首先咱们没遭遇啥反爬虫手段,没有用户的 cookie 认证啥的;我们还非常幸运地发现了直接获取 JSON 对象的 url,不然的话还得一个一个按投稿访问,会麻烦很多。
亲测试了一下,大概 15 分钟下载了 2 页的全部图片,并且 ip 没有被禁,挺好的,感谢 B 站,感谢壁纸喵 🥰